Resumen
Síntesis de resultados encontrados dento del análisis.
¿Cómo se Distribuye la Cantidad de Servicios?
En la exploracion de datos se observa que en Chile existen 4382 centros de salud, de los cuales la mayor parte se concentran en la región metropolitana. Luego las dos regiones con menor cantidad (57) de establecimientos son : la Región de Aysén del General Carlos Ibáñez del Campo y la Región de Magallanes y la Antártica Chilena
Además considerando que en el análisis se excluyeron; laboratorios, centros de las fuerzas armadas y servicios “médico local”. Solo existe una comuna en todo Chile sin centros de salud que es la Antártica

Correlación de variables
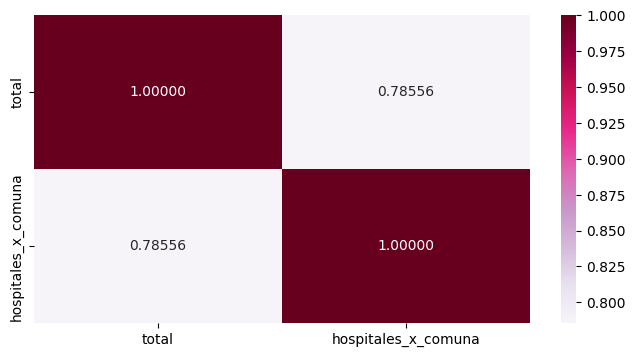
Para comprender si existía una relación numérica importante entre la densidad poblacional y la cantidad de establecimientos hospitalarios por comuna es que se realizó un merge de ambos dataframes (Censo2017 + Minsal), para operar sobre este. Para ello, se utilizó un mapa de calor que graficara la correlación.
Se ve una relacion importante entre estas dos variables puesto que es del 0.78. Esto permite elaborar de forma general que la cantidad de centros tendería a aumentar con el total de habitantes. Por lo que, debería de analizarse la existencia de más centros en pro de cubrir una mayor demanda de salud por parte de más ciudadanos. También podría realizarse un aumento en la capacidad de los establecimientos de las localidades. Es relevante destacar que si bien esta operación permite dar luces de cómo funciona esta relación y cuán alta es , no significa que haya una causalidad necesaria entre ambas.
Código asociado :
df_hospitales_poblacion_comuna = pd.merge(on="código_comuna", left=df_hospitales_1, right=df_poblacion_por_comuna[["código_comuna", "total"]], how="right")
conteo = df_hospitales_poblacion_comuna['código_comuna'].value_counts()
df_hospitales_poblacion_comuna['hospitales_x_comuna'] = df_hospitales_poblacion_comuna['código_comuna'].map(conteo)
df_hospitales_poblacion_comuna.drop_duplicates(subset="código_comuna", inplace=True)
correlation_matrix = df_hospitales_poblacion_comuna[["total", "hospitales_x_comuna"]].corr().round(5)
sns.heatmap(correlation_matrix, annot=True, fmt=".5f", cmap="PuRd")
Variable independiente (x) = Total de habitantes
Variable dependiente (y) = Centro de salud por comuna
Modelo Machine Learning : Regresión Lineal Simple
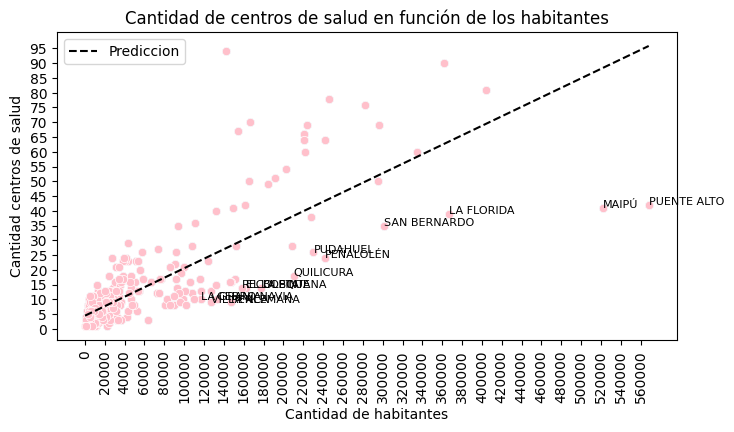
Considerando la correlación importante que se mostró en el mapa de calor entre la cantidad total de habitantes y la cantidad de establecimeintos de salud es que se establece un modelamiento con esta relación bivariable.
Las métricas de evaluación del modelo mostraron lo siguiente:
Métricas de Entrenamiento
- r^2 : 0.639641285766418
- RMSE 91.7316069668962
- Coeficientes: (0.0001607904136724008, 4.481244062907976)
Métricas de Prueba
- r^2 : 0.5177551943968883
- RMSE 88.83409328126801
Por lo tanto, en el caso de las métricas en el entrenamiento se puede decir que el r^2 no es el ideal pero no está bajo de 0.5 por lo que no es realmente un mal ajuste. En la métrica de prueba, este valor valor disminuye. Mostrando que la relación lineal entre ambos no está fuerte, pero aún así es significativa y puede ayudar como predicción.
Código asociado:
from sklearn.model_selection import train_test_split
train, test = train_test_split(df_hospitales_poblacion_comuna, test_size=0.25, random_state=2)
y_train = np.array(train['hospitales_x_comuna'])
y_test = np.array(test['hospitales_x_comuna'])
X_train = np.array(train['total'])
X_train = X_train.reshape(X_train.shape[0], 1)
X_test = np.array(test['total'])
X_test = X_test.reshape(X_test.shape[0], 1)
#realizar modelo
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
linreg = LinearRegression()
linreg.fit(X_train, y_train)
y_pred_train = linreg.predict(X_train)
r2_lineal_train = linreg.score(X_train, y_train)
rmse_train = mean_squared_error(y_train, y_pred_train)
#predecir valores de y para el set de prueba
y_pred_test = linreg.predict(X_test)
r2_lineal_test = linreg.score(X_test, y_test)
rmse_test = mean_squared_error(y_test, y_pred_test)
Densidad como parámetro
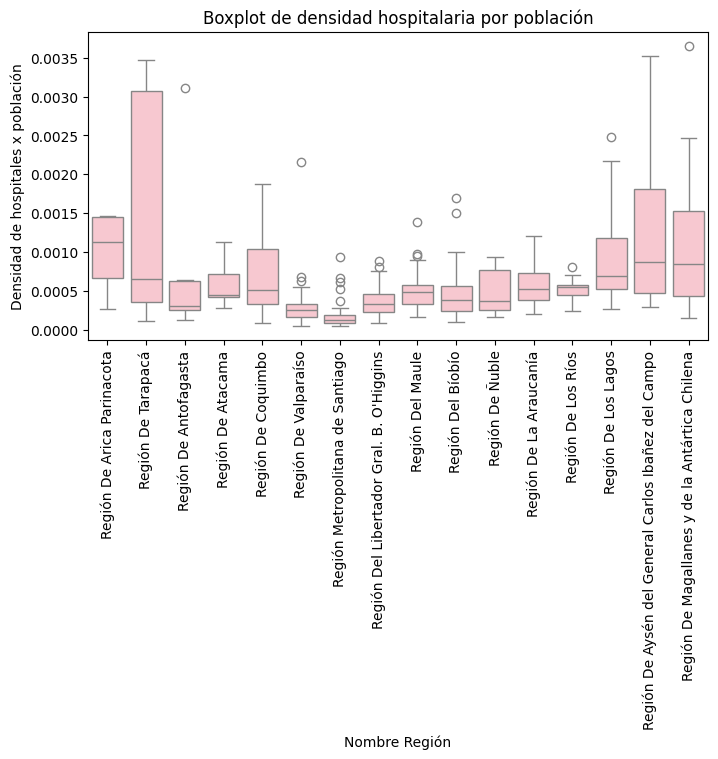
En paralelo al análisis anterior, se utiliza la variable de densidad de hospitales por personas de una comuna, para conocer la distribución que existe comparativamente entre regiones. Sin embargo se reconoce que no es un parámetro representativo para realizar un análisis considerando que se puede observar que hay comunas grandes como en la region de Tarapaca que aunque tengan 1000 habitantes tienen 6 centros de salud. Debido a que estos habitantes estan muy dispersos.
Existencia de Urgencias
En la contabilización global sin separación por ninguna división geográfica, la mayoría de centros médicos (todos sin separación por tipo) no tienen servicio de urgencias, predominando el valor False con 3784 entradas. Por lo tanto, solo 741 si cuentan con urgencias de cualquier tipo.
Luego en la búsqueda específica por región se tiene que no hay ninguna región que no tenga al menos un servicio de médico sin urgencias (de cualquier tipo).
- Analizando los valores de todas las regiones en conjunto, la que tiene más servicios con urgencias es la Metropolitana con 177. Que a fecha de 2017 es también la con más población, 7.122.808.
- La que tiene menos servicios de urgencia analizando todos los valores regionales en conjunto es la de Arica y Parinacota con 5. Su población a 2017 era de 226.068
- En el porcentaje que equivale al total de centros con urgencia sobre el total de centros por cada región individual, la región con el más alto sobre las otras regiones fue Valparaíso con un 21,09%. Que tiene a 2017 una población de 1.815.902.
- En el cálculo de porcentajes anteriores, en la región Metropolitana los centros con urgencia médica sobre su total de centros, equivale a 18,15%
- La región con número más bajo de centros con urgencia sobre el total de centros de la región sola, comparado con las otras regiones es la región de Arica y Parinacota con 6,9%. Por lo que, al ser menos de la mitad respecto al porcentaje mayor debería analizarse una mayor implementación de servicios con urgencias.
Por provincia (dividida internamente por comuna) se observó según los gráficos que las comunas sin servicio de urgencia son :
- Las Torres del Paine, en la provincia de Última Esperanza (22.686 habitantes)
- Timaukel y Primavera, en la provincia de Tierra del Fuego (8364 habitantes)
- San Gregorio, Río Verde y Laguna Blanca , en la provincia de Magallanes (133.282 habitantes)
- Río Ibañez, provincia de General Carrera (7531 habitantes)
- O´higgins y Tortel, en la provincia de Capitán Prat (4638 habitantes)
- Lago Verde, en la provincia de Coyhaique (58.670 habitantes)
- Lumaco, Ercilla, Los Sauces y Renaico, en la provincia de Malleco (205.124 habitantes)
- Palmilla y Pumanque, en la provincia de Colchagua (22.556 habitantes)
- Quinta de Tilcoco, provincia de Cachapoal (646.133 habitantes)
- Panquehue, provincia de San Felipe de Aconcagua (154.718 habitantes)
- La Cruz, provincia de Quillota (203.277 habitantes)
- San Esteban y Rinconada , provincia de Los Andes (110.602 habitantes)
- Ollague , provincia de El Loa (177.048 habitantes)
- General lagos, provincia de Parinacota (3449 habitantes)
- Camarones, provincia de Arica (22.619 habitantes)
- Guaitecas, provincia de Aysén (32.319 habitantes)
Hay 25 comunas que no tienen centros médicos con servicio de urgencia de cualquier tipo. Considerando que en el dataframe, no se consideraba la comuna de la Antártica, es que se contabiliza y analiza por separado. En esta tampoco habían urgencias por lo que en total son 26.
Finalmente en la tabla resumen se observa lo siguiente : en la columna de “false” se contabiliza aquellos centros que no tienen ningún tipo de urgencia y la de “true” los que sí. Sin embargo, se filtró para dejar solo los que tenían el valor en la variable true como 0. Para así sumar de forma más fácil.
| Tiene Servicio de Urgencia | Nombre Comuna | false | true |
|---|---|---|---|
| 1 | CAMARONES | 1 | 0 |
| 6 | ERCILLA | 6 | 0 |
| 1 | GENERAL LAGOS | 1 | 0 |
| 1 | GUAITECAS | 1 | 0 |
| 1 | LA CRUZ | 1 | 0 |
| 3 | LAGO VERDE | 3 | 0 |
| 1 | LAGUNA BLANCA | 1 | 0 |
| 5 | LOS SAUCES | 5 | 0 |
| 7 | LUMACO | 7 | 0 |
| 1 | O’HIGGINS | 1 | 0 |
| 1 | OLLAGÜE | 1 | 0 |
| 4 | PALMILLA | 4 | 0 |
| 1 | PANQUEHUE | 1 | 0 |
| 1 | PRIMAVERA | 1 | 0 |
| 3 | PUMANQUE | 3 | 0 |
| 2 | QUINTA DE TILCOCO | 2 | 0 |
| 2 | RENAICO | 2 | 0 |
| 1 | RINCONADA | 1 | 0 |
| 5 | RÍO IBÁÑEZ | 5 | 0 |
| 1 | RÍO VERDE | 1 | 0 |
| 5 | SAN ESTEBAN | 5 | 0 |
| 1 | SAN GREGORIO | 1 | 0 |
| 1 | TIMAUKEL | 1 | 0 |
| 1 | TORRES DEL PAINE | 1 | 0 |
| 1 | TORTEL | 1 | 0 |
Sobre las clasificaciones en los Servicios
Respecto a las distintas categorías en las que se dividían los centros médicos y en correlación con las conclusiones del ítem previo es que se ve el tipo de urgencias y el nivel de complejidad (véanse el apartado de definiciones).
Tipo de Urgencias
- No hay ninguna región que tenga todos los tipos de urgencia
- Las cateogrías con cantidades más bajas son Ambulatoria Especializada (1 en Región Metropolitanan) y Urgencia Ambulatoria (1 en Región de los Lagos)
- En total tipo de urgencia más recurrente es Urgencia Hospitalaria (UEH) con 248 recintos, le sigue Urgencia Ambulatoria (SAPU) con 234 y Urgencia Ambulatoria (SUR) con 159.
Existencia de servicios por complejidad:
- Todas las regiones tienen al menos un centro de salud de alta , mediana o baja complejidad
- Existen 290 comunas de 346 que no tienen hospitales de alta complejidad
- Existen 206 comunas de 346 que no tiene hospitales de mediana complejidad
- No hay comunas que no tengan hospitales de baja complejidad


Distribución de Farmacias
En este apartado se hace un rastreo de la existencia de farmacias a lo largo del territorio Chileno en el presente año. Concluyéndose que en el filtrado del dataframe por provincia existen solo 2 que no tienen farmacias : Parinacota y La Antártica.
| código_comuna | cantidad_farmacias_comuna | orden | nombre_región | código_región | nombre_provincia | código_provincia | nombre_comuna | edad | hombres | mujeres | total | cantidad_farmacias_prov | cantidad_farmacias_reg | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 15201.0 | 0.0 | 66 | ARICA Y PARINACOTA | 15.0 | PARINACOTA | 152.0 | PUTRE | Total Comunal | 2054 | 711 | 2765 | 0.0 | 67 | 0 |
| 3 | 15202.0 | 0.0 | 88 | ARICA Y PARINACOTA | 15.0 | PARINACOTA | 152.0 | GENERAL LAGOS | Total Comunal | 412 | 272 | 684 | 0.0 | 67 | 0 |
| 339 | 12201.0 | 0.0 | 7480 | MAGALLANES Y DE LA ANTÁRTICA CHILENA | 12.0 | ANTÁRTICA CHILENA | 122.0 | CABO DE HORNOS | Total Comunal | 1195 | 868 | 2063 | 0.0 | 41 | 0 |
| 340 | 12202.0 | 0.0 | 7502 | MAGALLANES Y DE LA ANTÁRTICA CHILENA | 12.0 | ANTÁRTICA CHILENA | 122.0 | ANTÁRTICA | Total Comunal | 126 | 12 | 138 | 0.0 | 41 | 0 |
Por otro lado, aquellas comunas sin farmacias suman 43. Generando una relación con la categoría de urgencias, hay repetición de algunas de estas, en aquellas que tenían falta de cualquier tipo de urgencia. Siendo las siguientes :
- Primavera,
- Ollague
- Camarones
- Gral lagos
- O´higgins
- Río Ibañez
- Tortel
- Lago verde
- Palmilla
- Pumanque
- Panquehue
- Torres del paine
- Laguna blanca
- San gregorio
- Río verde.
Por lo que, existiría una carencía en ambos ámbitos dentro de estas localidades. Debíendo considerarse un plan de implementación de estos servicios según necesidades específicas de la población. El riesgo de la población que no tiene urgencias y farmacias en su alrededor es importante, respecto a las garantías que el Estado tendría que proveer.
Correlaciones
Para conocer la relación entre la variable de cantidad total de personas por comuna y las farmacias por comuna se utiliza la función .corr donde se obtiene numéricamente el valor de correlación entre ambas variables.
Es un valor bastante alto de 0.849 aproximadamente. Indicando que existe una relación importante entre mayor cantidad de farmacias a mayor cantidad de población en una comuna y lo mismo en caso de un menor valor. Esto en la generalidad de los casos
df_farmacias_cantidad[["cantidad_farmacias_comuna", "total"]].corr(numeric_only=True)
| cantidad_farmacias_comuna | total | |
|---|---|---|
| cantidad_farmacias_comuna | 1.000000 | 0.849409 |
| total | 0.849409 | 1.000000 |

Sobre los Servicios Médicos Públicos y Privados
Dentro del estudio de los datos, también se busca conocer como es que funciona la distribución de centros médicos según su clasificación en público o privado. Para conocer de forma sintética y clara solo la cantidad de servicios públicos y privados por comuna , se realiza una pivot table.
cantidad_publicos_privados_comuna = pd.pivot_table(df_hospitales_1,
index='código_comuna',
columns='tipo_de_prestador_sistema_de_salud',
aggfunc='size', ) #Función size para conocer la cantidad
#Agrupar cantidad de servicios público/privado en cada comuna
df_hospitales_poblacion_comuna_publico_privado = pd.merge(df_hospitales_poblacion_comuna, cantidad_publicos_privados_comuna, on="código_comuna")
#Nueva columna para saber la diferencia en cantidad de público y privado
df_hospitales_poblacion_comuna_publico_privado["diferencia_publico_menos_privado"] = df_hospitales_poblacion_comuna_publico_privado["Público "] - df_hospitales_poblacion_comuna_publico_privado["Privado"]
df_hospitales_poblacion_comuna_publico_privado.sort_values(by="diferencia_publico_menos_privado", ascending=True, inplace=True)
df_hospitales_poblacion_comuna_publico_privado["nombre_comuna"]
Correlaciones
Para conocer la relación entre la variable de cantidad total de prestador por comuna y los tipos de prestadores por comuna, es que se utiliza el gráfico de scatterplot. Ello debido a que por medio de la simbolización dividida de datos en puntos y triángulos es que se permite ver si existe alguna correlación a simple vista entre ambas.
Además se utiliza un mapa de calor para la correlación entre 4 variables : la cantidad de hospitales por comuna, clasificación de público, clasificación de privado y el total poblacional.
sns.heatmap(df_hospitales_poblacion_comuna_publico_privado[["hospitales_x_comuna", "Privado","Público ", "total"]].corr(), annot=True)
-
En cuanto a la variedad regional existe una mayor variedad de establecimientos de acceso publico que privado exceptuando por la 1era y tercera región; donde la mayor variedad de establecimientos publicos que se encuentre en la region de la Araucanía, mientras que la mayor variedad de establecimientos privados es en la region de Antofagasta.
-
En la variedad comunal existe una mayor variedad de establecimientos privados en 26 regiones donde la comuna con mayor variedad es la comuna de Providencia, con mayor variedad de establecimientos privados, mientras que la comuna de Los Ángeles posee la mayor variedad de establecimientos publicos.



Modelo de Machine Learning 2: Clustering
Para realizar esta parte del estudio se realizó una limpieza focalizada de los datos, para obtener un análisis más claro.
df_hospitales_P4 = df_hospitales.dropna(subset=['latitud', 'longitud', 'nivel_de_complejidad'])
#se pasa el dataframe de hospitales a un geodaframe para poder hacer uso de los métodos que se incluyen en geopandas
gdf_hospitales = gpd.GeoDataFrame(
df_hospitales_P4, geometry=gpd.points_from_xy(df_hospitales_P4.longitud, df_hospitales_P4.latitud), crs="EPSG:5360"
)
#Se renombran algunas columnas para una lectura más simplificada y además se establece que el sistema de coordenadas de los valores en la columna "geometry" será crs 5360
comunas = gpd.read_file('./maps/Comunas.zip') # se lee el archivo
comunas.rename(columns={'codregion': 'código_región', 'Region': 'nombre_región', 'Comuna': 'comuna'}, inplace=True)
comunas['geometry'] = comunas['geometry'].to_crs(5360) #Sistema de representación de coordenas de seleccionado
Modelo de Clustering : “DBSCAN”
#Se seleccionan : los valores a utilizar (latitud y longitud), el epsilon (representando el grado de distancia ) y la cantidad mínima de clusters que pueden existir.
from sklearn.cluster import DBSCAN
hospitals_data = gdf_hospitales[['latitud', 'longitud']].values
eps = 0.1 #valor del epsilon
min_samples = 3 #valor mínimo de clusters
dbscan = DBSCAN(eps=eps, min_samples=min_samples)
gdf_hospitales['Cluster'] = dbscan.fit_predict(hospitals_data) #Entrenamiento del modelo
# Gráfico del modelo
for i in range(1, 17):
gdf_selected_region = comunas[comunas['código_región'] == i]
gdf_selected_region_hospitals = gdf_hospitales[gdf_hospitales['código_región'] == i]
overlay = gdf_selected_region.overlay(gdf_selected_region_hospitals, how="union", keep_geom_type=False)
overlay['Cluster'] = overlay['Cluster'].fillna(-2)
fig, ax = plt.subplots(figsize=[20, 20])
# Establecer el color de fondo del eje
ax.set_facecolor("white")
ax.set_title(gdf_selected_region["nombre_región"].unique()[0])
# Establecer el color de fondo de la superposición
overlay.plot(column="Cluster", ax=ax, edgecolor="black", linewidth=0.55, facecolor="none", legend=False)
plt.show()
Para obtener un resumen de cómo estaban estructurados los clusters respecto a los centros de distintas complejidaddes que contenían se utilizó este código, cambiando el número de cuántos establecimientos tenía y luego con un len para el total.
clusters_sin_dos = set()
for i in gdf_hospitales['Cluster'].unique():
cluster = gdf_hospitales[gdf_hospitales['Cluster'] == i]#Recorre cada cluster e imprime la información de cada uno
print(f"El cluster {i} tiene centros de salud de complejidades {cluster['nivel_de_complejidad'].unique()}")
print()
if len(cluster['nivel_de_complejidad'].unique()) < 2:#Si tiene solo un nivel de complejida lo agrega al set que contiene este tipo de clusters
clusters_sin_dos.add(i)
- Existen 105 clusters que no tienen todos los niveles de complejidad
- Hay 84 clusters que tienen establecimientos con un solo nivel de complejidad, siendo todos estos de baja complejidad.
Justificación del modelo
-
Se escoge el modelo de DBSCAN, o llamado agrupación/clustering por densidad, el cuál es un algoritmo de aprendizaje no supervisado de Machine Learning. Pues se necesita conocer qué centros de salud forman una red por ubicación geográfica. Para saber si es posible el traslado entre centros de salud y ver si todas estas redes contienen los 3 tipos de complejidad. Con el fin de averiguar si las personas podrían tener problemas en buscar atención adecuada.
- Para hacer el modelo se hace uso de las variables de : latitud y longitud del dataframe de los hospitales(gdf_hospitales).Con estas variables se calcula la distancia cartesiana entre centros de salud.
- Se seleciona un ε de 0.1, ya que este radio nos entrega una cobertura óptima de redes que contienen centros de todas las complejidades, mientras que al mismo tiempo separa redes más pequeñas que son las que nos interesa analizar con mayor profundidad.
- Destacar en este caso no se considera como necesario normalizar los datos puesto que son coordenadas y no valores valores numericos que representen una cantidad.
- Al ser un modelo de aprendizaje no supervizado, no hay validaciones a realizar. Debido a que es el modelo el que encuentra la solución y no hay etiquetas para saber si el modelo está correcto.


